
Date selected to be approximately one year from prediction statement, and approximately two years from this paper: https://huggingface.co/papers/2402.04494
1800 elo selected as the approximated elo for GPT-3.5-Turbo-Instruct, rounded up to the nearest 100 elo points.
Lines defines as any series of moves that when viewed collectively could easily be explained to a human observer through human understandable heuretics, material exchanges, centipawn differences, or predicted win rates.
Elo requirement necessary so that explanation of potential lines is not alone sufficient, they must be competitive. For sake of rigor, the model must be able to provide three potential lines, if that many exist for the given position, within a single prompt without any further conversation turns, messages, or prompts from a human user.
 1,000
1,000Gemini 3 is 500+ pts better than 3.5 turbo instruct per: https://dubesor.de/chess/chess-leaderboard
I’m pretty sure it can explain 3 lines
What kind of harness is allowed to mitigate hallucinations?
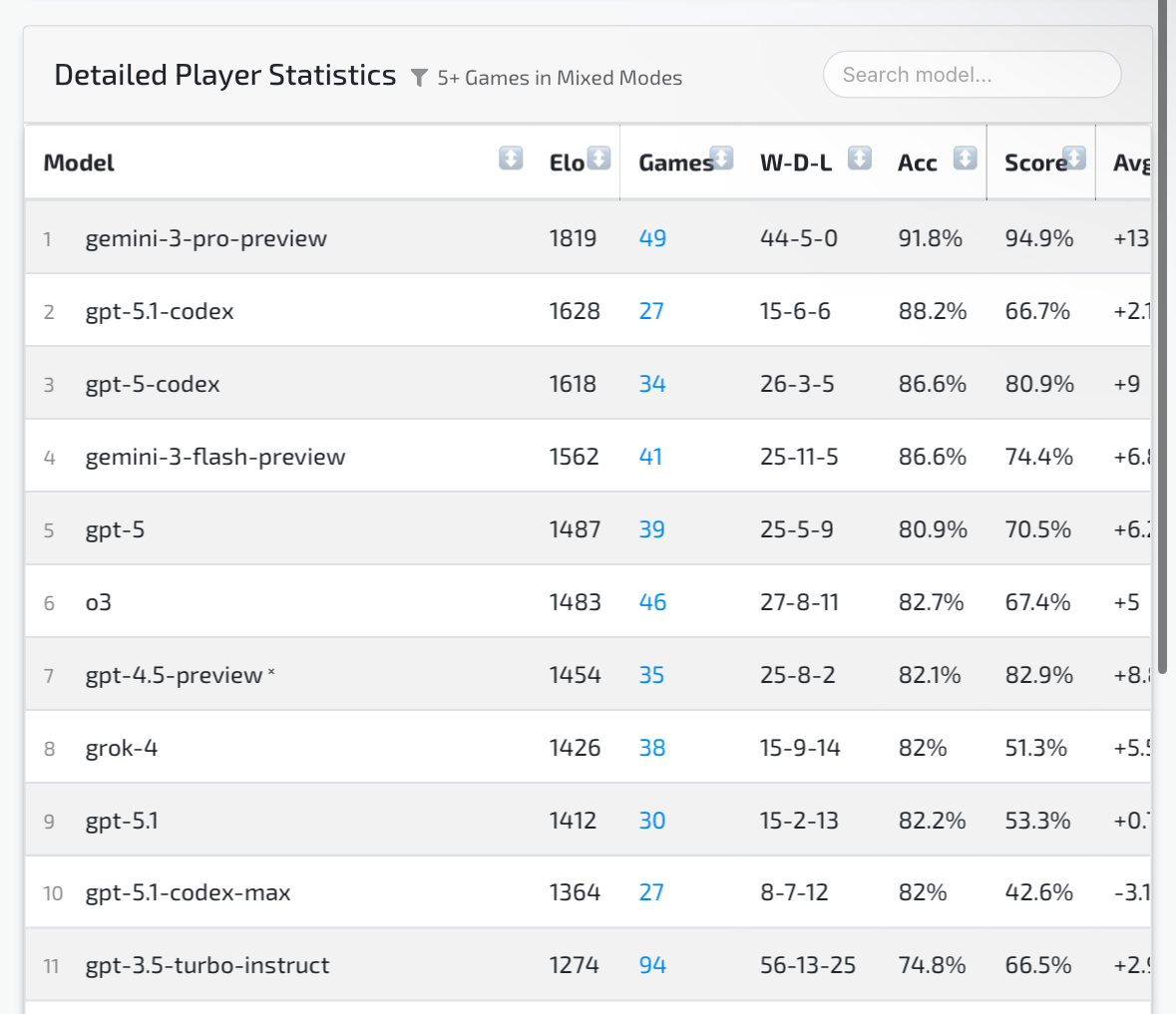
note it takes over 4000 tokens per move in “reasoning mode” which might be considered unacceptable amounts of latency

Vs only ~200 in continuation mode (where pretraining wins and GPT-4.5 excels)
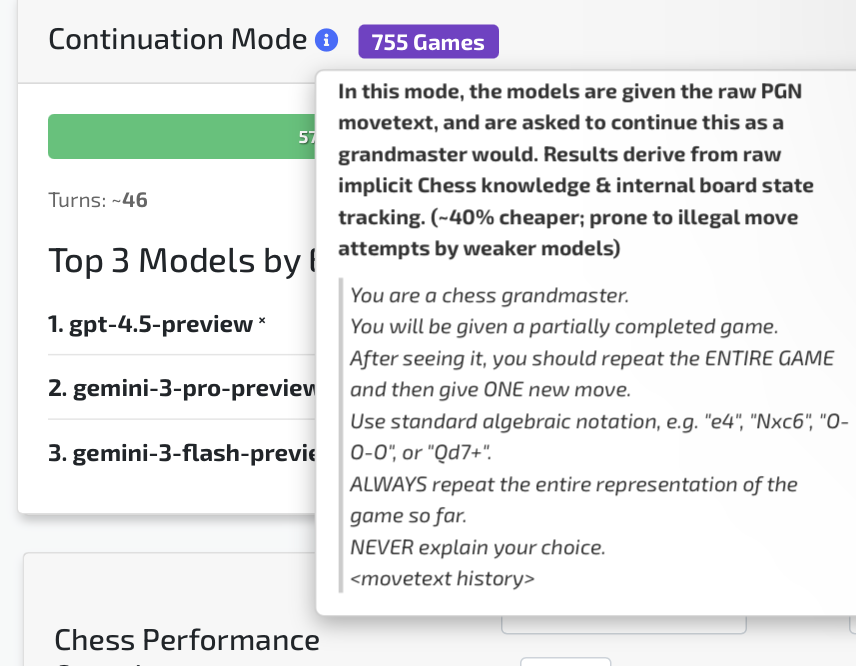
I’m guessing you’re only talking about LLM (LRMs)
so I think Gemini 3 is probably the best candidate
If you’re talking about only transformer models the ChessGPT from over 2 years ago, can easily generate those lines (here’s my demo of that model from last month: https://chess-llm-316391656470.us-central1.run.app, and my full write up if you care/want the full context:https://chinmaysnotebook.substack.com/p/chessllm-what-a-50m-transformer-says ) just from sampling the logits and it’s quite humanlike in its play.
I think it’s promising to look into whether fine tuning that model would be a good way to emulate a specific player, I also want to look into the mech interp work to find “reasoning circuits”
Maybe the crux of the market is whether “hallucinations are solved” since I think if the threshold is like 50% accuracy Gemini 3 Pro probably passes, but if you need 90% accuracy I think it’ll fail.
Quick test let me take the most recent game I played
“For sake of rigor, the model must be able to provide three potential lines, if that many exist for the given position, within a single prompt without any further conversation turns, messages, or prompts from a human user.”
I know pasting a PGN into a chatbot gives you a semi accurate summary of the game (with glazing to say you played like a GM even if you’re barely 1500)
Ok lets fact check the summary it gave solely based on the URL (was able to fetch the pgn by itself)

point one is largely accurate
point two is also technically correct, but somewhat shallow analysis
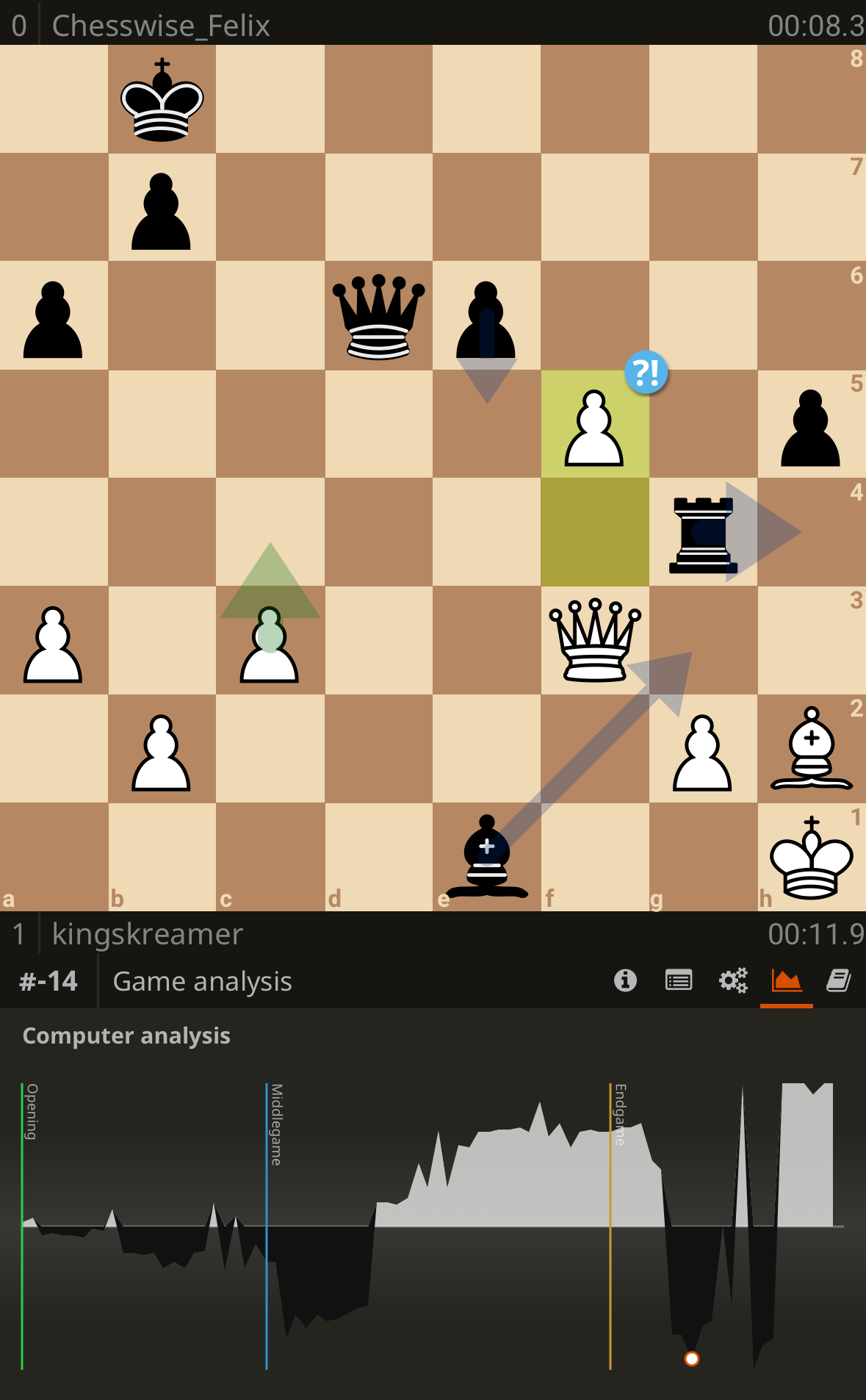
point 3 is also accurate based on the game but fails to state to the obvious (it’s a blunder because it drops the queen, and the following move hangs mate in 1)
point 4 incorrectly says White has 2 queens
So in general the analysis is quite passable for this markets criteria, but highlights the hallucination rate (~20%)
Same test for Claude Opus 4.5

Pretty similar, passable not great analysis
[Event "Rated Bullet game"]
[Site "https://lichess.org/QotzB1R0"]
[Date "2026.01.24"]
[White "kingskreamer"]
[Black "Chesswise_Felix"]
[Result "1-0"]
[WhiteElo "2050"]
[BlackElo "2062"]
[Variant "Standard"]
[TimeControl "60+0"]
[ECO "B10"]
[Opening "Caro-Kann Defense: Hillbilly Attack"]
[Termination "Time forfeit"]
1. e4 c6 2. Bc4 d5 3. exd5 cxd5 4. Be2 Nf6 5. Nf3 e5 6. d3 Nc6 7. Bg5 Bb4+ 8. Nbd2 h6 9. Bh4 g5 10. Bg3 Qc7 11. h4 g4 12. Nh2 Be6 13. a3 Bd6 14. f4 e4 15. dxe4 dxe4 16. O-O O-O-O 17. Nxg4 Nxg4 18. Bxg4 Bxg4 19. Qxg4+ Kb8 20. Nxe4 Qb6+ 21. Kh1 Be7 22. Bf2 Qc7 23. Rad1 Rxd1 24. Rxd1 h5 25. Qf3 a6 26. Nc5 Rg8 27. Ne4 Nd8 28. Ng5 Ne6 29. Nxe6 fxe6 30. Re1 Qd6 31. c3 Rg4 32. Bg3 Bxh4 33. Bh2 Bxe1 34. f5 e5 35. f6 Bg3 36. f7 Qd1+ 37. Bg1 Qxf3 38. gxf3 Rg5 39. f8=Q+ Kc7 40. Qf6 Kb8 41. Qf8+ 1-0
Ok this comment is getting unnecessarily long, but no one’s gonna read it anyways:
Just the PGN without metadata to Gemini:
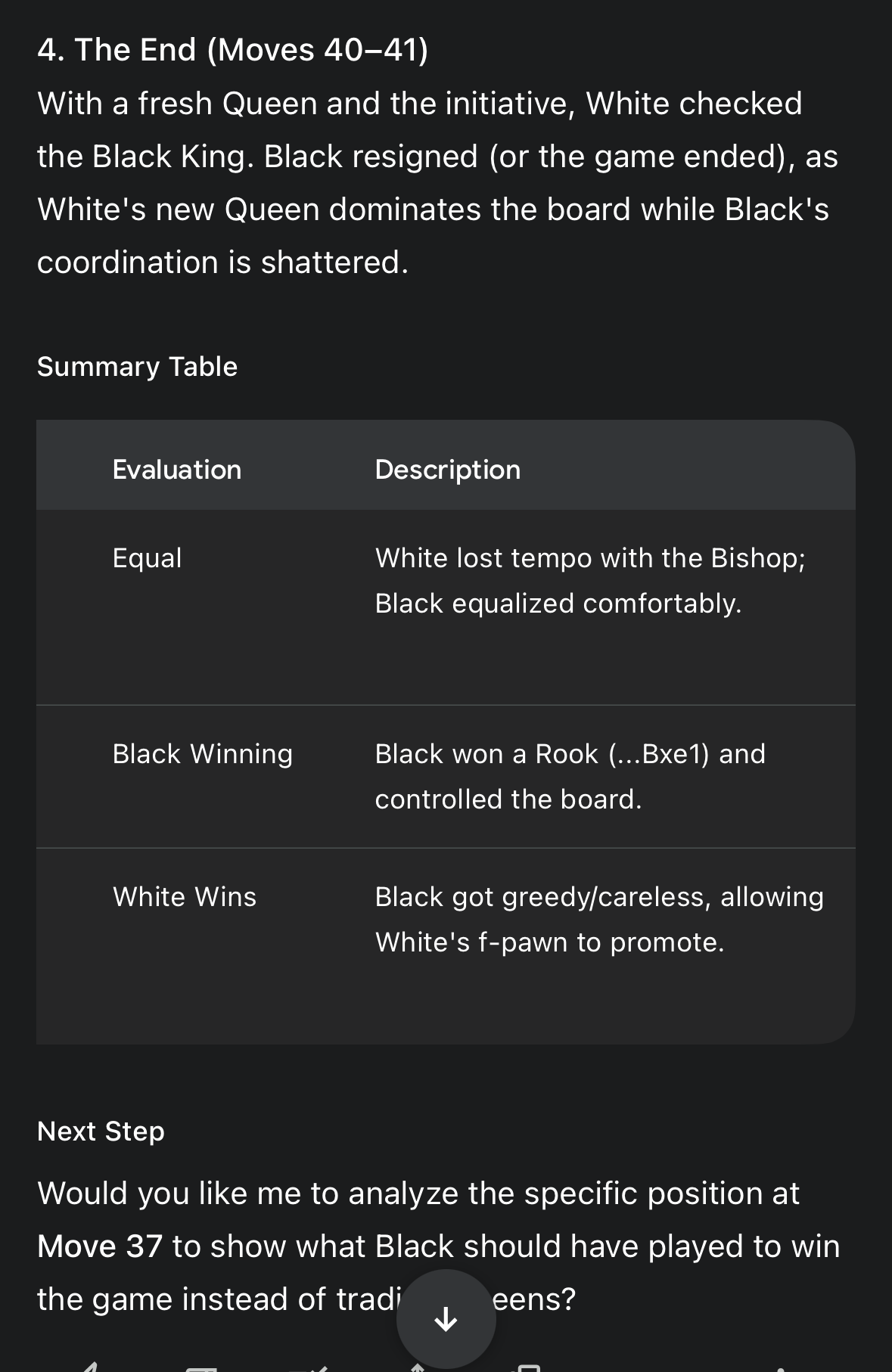
Response is still generally coherent
Now let’s look at the move 37 it wanted to analyze further (there’s a mate in 1, can it find it?)
It does find the right move (Rh4+ (should be #))

But the analysis is only halfway correct

This definitely looks like a fail
Now I guess we haven’t tested Gemini 3 Deep Think or Claude Code with access to a computer
Ok simplify this
This prompt finds the checkmate on all 3 modes (Fast, Thinking, Pro)
“You are a chess grandmaster.
You will be given a partially completed game.
After seeing it, you should repeat the ENTIRE GAME and then give ONE new move.
Use standard algebraic notation, e.g. "e4", "Nxc6", "O-O-O", or "Qd7+".
ALWAYS repeat the entire representation of the game so far.
NEVER explain your choice.
1. e4 c6 2. Bc4 d5 3. exd5 cxd5 4. Be2 Nf6 5. Nf3 e5 6. d3 Nc6 7. Bg5 Bb4+ 8. Nbd2 h6 9. Bh4 g5 10. Bg3 Qc7 11. h4 g4 12. Nh2 Be6 13. a3 Bd6 14. f4 e4 15. dxe4 dxe4 16. O-O O-O-O 17. Nxg4 Nxg4 18. Bxg4 Bxg4 19. Qxg4+ Kb8 20. Nxe4 Qb6+ 21. Kh1 Be7 22. Bf2 Qc7 23. Rad1 Rxd1 24. Rxd1 h5 25. Qf3 a6 26. Nc5 Rg8 27. Ne4 Nd8 28. Ng5 Ne6 29. Nxe6 fxe6 30. Re1 Qd6 31. c3 Rg4 32. Bg3 Bxh4 33. Bh2 Bxe1 34. f5 e5 35. f6 Bg3 36. f7 Qd1+ 37. Bg1”
And then this modification produces 3 lines:
You are a chess grandmaster.
You will be given a partially completed game.
After seeing it, you should repeat the ENTIRE GAME and then give up Three potential lines/moves (expressed as variations in the PGN) move.
Use standard algebraic notation, e.g. "e4", "Nxc6", "O-O-O", or "Qd7+".
ALWAYS repeat the entire representation of the game so far.
NEVER explain your choice.
1. e4 c6 2. Bc4 d5 3. exd5 cxd5 4. Be2 Nf6 5. Nf3 e5 6. d3 Nc6 7. Bg5 Bb4+ 8. Nbd2 h6 9. Bh4 g5 10. Bg3 Qc7 11. h4 g4 12. Nh2 Be6 13. a3 Bd6 14. f4 e4 15. dxe4 dxe4 16. O-O O-O-O 17. Nxg4 Nxg4 18. Bxg4 Bxg4 19. Qxg4+ Kb8 20. Nxe4 Qb6+ 21. Kh1 Be7 22. Bf2 Qc7 23. Rad1 Rxd1 24. Rxd1 h5 25. Qf3 a6 26. Nc5 Rg8 27. Ne4 Nd8 28. Ng5 Ne6 29. Nxe6 fxe6 30. Re1 Qd6 31. c3 Rg4 32. Bg3 Bxh4 33. Bh2 Bxe1 34. f5 e5 35. f6 Bg3 36. f7 Qd1+ 37. Bg1
Ok now test on different positions with the prompt template:
You are a chess grandmaster.
You will be given a partially completed game.
After seeing it, you should repeat the ENTIRE GAME and then give AT LEAST THREE potential lines/moves (expressed as variations in the PGN) move.
Use standard algebraic notation, e.g. "e4", "Nxc6", "O-O-O", or "Qd7+".
ALWAYS repeat the entire representation of the game so far.
NEVER explain your choice.
Finally append a brief JSON with the reasoning for each line
Respond with a JSON object containing your reasoning and move:
{
"reasoning": "<your analysis and explanation>",
"move": "<your chosen move in EXACT SAN format>"
}
1. e4 c6 2. Bc4 d5 3. exd5 cxd5 4. Be2 Nf6 5. Nf3 e5 6. d3 Nc6 7. Bg5 Bb4+ 8. Nbd2 h6 9. Bh4 g5 10. Bg3 Qc7 11. h4 g4 12. Nh2 Be6 13. a3 Bd6 14. f4 e4 15. dxe4 dxe4 16. O-O O-O-O 17. Nxg4 Nxg4 18. Bxg4 Bxg4 19. Qxg4+ Kb8 20. Nxe4 Qb6+ 21. Kh1 Be7 22. Bf2 Qc7 23. Rad1 Rxd1 24. Rxd1 h5 25. Qf3 a6 26. Nc5 Rg8 27. Ne4 Nd8 28. Ng5 Ne6 29. Nxe6 fxe6 30. Re1 Qd6 31. c3 Rg4 32. Bg3 Bxh4 33. Bh2 Bxe1 34. f5 e5 35. f6 Bg3 36. f7 Qd1+ 37. Bg1
Yeah Gemini 3 Fast Aces this test (other models from OpenAI, Anthropic, ZAI, Deepseek tend to fail, Grok is by far the worst suggesting taking the f7 pawn whereas the others only make slight errors)
This matches up with the perception of Gemini 3 as the best of the old pretraining heavy models whereas other models tend to be “benchmaxxed” especially on coding bench marks with a focus on agentic use cases (sharpening output distribution at the cost of the tails)
This aligns with a benchmark like SimpleBench where Gemini 3 Pro is in its own class for tasks related to spacial reasoning while GPT-5.2 actually regressed from GPT-5 due to being more focused on common use cases hindering niche capabilities like chess.
Ok I’ve wasted way too much time on this lol, someone should create a simple web app to test whether this prompt (or others is sufficient to resolve yes)